System Design Interview: Decentralized Web Crawler
The video version covers each design decision in more detail, with worked examples and tradeoff discussions.
Understand the problem
What we’re building. A web crawler that runs across independent nodes with no central component. In a distributed crawler, many machines work together, but they still share infrastructure: a common URL queue, a common scheduler, a common database that tracks what has been crawled. In a decentralized crawler, none of that shared infrastructure exists. Each node runs independently, and the nodes have to agree on who crawls what without anyone coordinating them.
Functional requirements
Core:
- Start from seed URLs and crawl reachable pages.
- Fetch each page roughly once (deduplicate URLs).
- Stay polite: honor
robots.txtand per-host rate limits.
Below the line (out of scope):
- Building a search index or ranking results
- Rendering JavaScript / headless browsing
- The storage format for page content
Non-functional requirements
Core:
- Decentralized: no central coordinator and no single point of failure.
- Scale: billions of URLs across thousands of nodes (10,000 nodes is the running number).
- Fault tolerant under churn: nodes join, leave, and crash constantly; crashes happen without warning.
- Eventual coverage: almost every reachable page gets crawled; occasional duplicates and rare long-tail misses are acceptable.
Below the line:
- Strong consistency or exactly-once crawling
Accepting eventual coverage, with occasional duplicates, is what makes the rest of the design cheap. It removes the need for the cross-node coordination that strong consistency would require.
The set-up
Core entities:
- Node: one machine running a full local crawler. The system has thousands of these, each operating independently.
- Crawl task: a URL that needs to be fetched. Each URL gets hashed into a number, called its crawl task key, which determines which node is responsible for it.
- Owner node: the node that a URL’s key maps to. The owner deduplicates and eventually crawls all URLs whose keys fall in its range.
- Seen set: the set of URLs an owner has already seen. When a new URL arrives, the owner checks this set to decide whether to crawl it or discard it as a duplicate.
- The ring: a circular number space that all nodes share. Each node sits at a position on this ring, and each URL’s key also maps to a position. The ring determines which node owns which key. The mechanism behind it is consistent hashing, explained below.
The interface. The system needs only two operations. The first is lookup(key): given a crawl task key, it returns the node that owns it. The second is send(task, owner): it hands a crawl task to that owner node.
lookup(key) # -> owner node
send(task, owner)When a node discovers a new URL, it hashes the URL to get a key, calls lookup to find the owner, and calls send to hand off the URL. The rest of the design is about making lookup return the correct answer quickly, even as nodes join, leave, and crash.
High-level design
On a single machine, a crawler is one loop. It pulls a URL from its queue, fetches the page, parses the HTML for links, and adds any new links back to the queue. A seen set tracks which URLs have already been processed, so the crawler never fetches the same page twice.
The decentralized version changes one thing. When a node fetches a page and finds new links, it does not add them to its own queue. Instead, it sends each link to the one node responsible for it: the link’s owner.
Here is a concrete example. Node A is crawling a page and finds a link to example.com/page. Node A hashes that URL to get key 63, then calls lookup(63), which returns node B. Node A sends the link to node B.
Node B checks its seen set: has it seen this URL before? If not, it adds the URL to its own queue and will eventually fetch it. When node B crawls that page, it finds more links, hashes each one, looks up the owner, and sends them along. The cycle repeats until the reachable web is covered.
This is how deduplication works without a central database. The same URL always hashes to the same key, and the same key always maps to the same owner. Even if a hundred different nodes all discover the same link, every copy ends up at the same owner node. That node checks one seen set and either queues the URL or drops it as a duplicate.
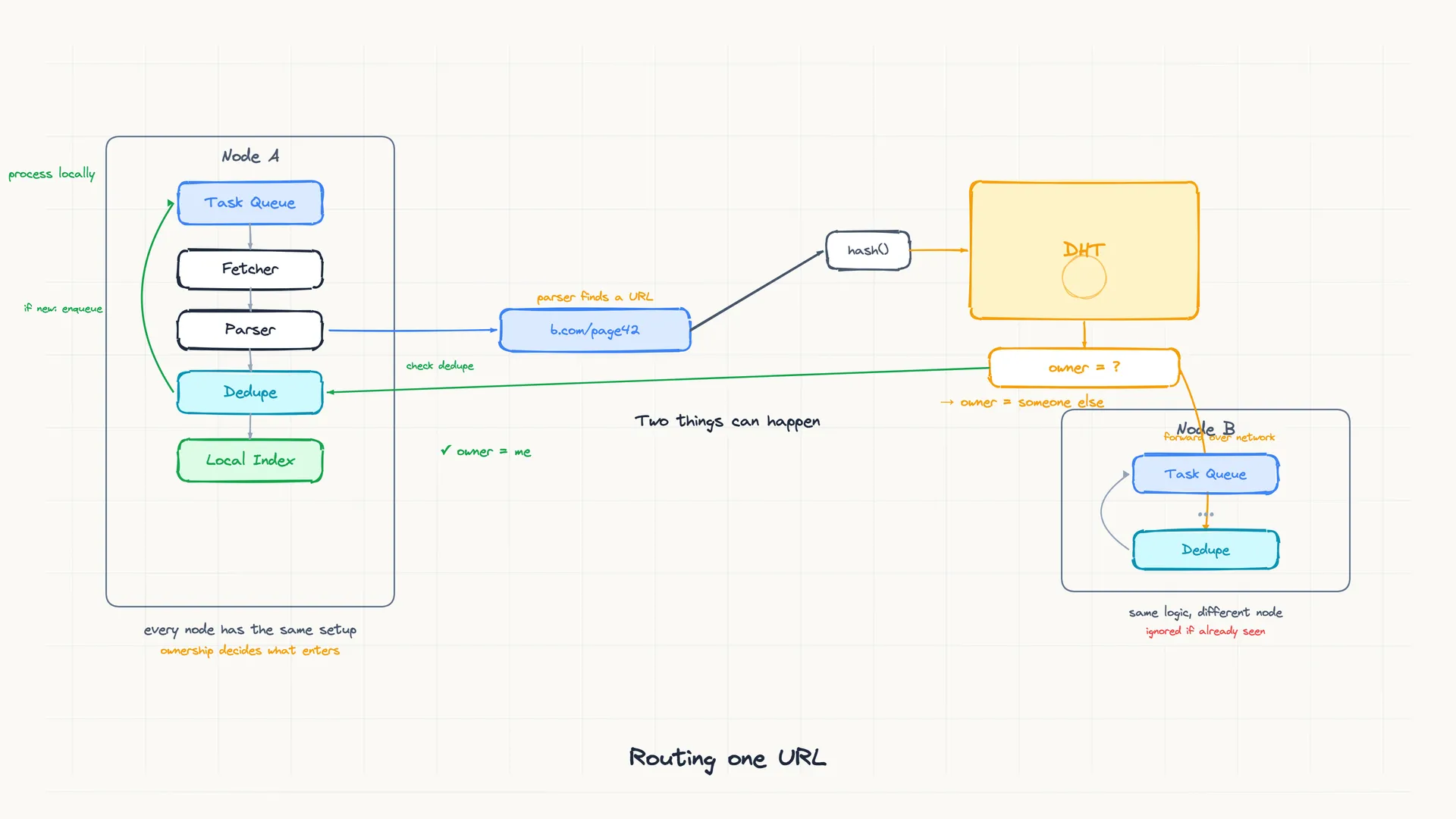
Each node plays two roles at the same time. It is a crawler, working through its own queue and sending discovered links to their owners. It is also an owner for a range of keys, receiving links from other nodes, checking them against its seen set, and queuing the new ones. The two roles run as two loops:
# crawl loop: work through this node's own queue
for url in my_queue:
page = fetch(url)
for link in parse(page):
key = hash(link)
owner = lookup(key) # the ring maps a key to its owner, no coordinator
send(link, owner) # the owner may be this node
# receive handler: a link routed here because this node owns its key
def on_receive(link):
if link not in seen_set: # crawl each link once
seen_set.add(link)
my_queue.add(link)Seed URLs start the process by priming a few nodes’ queues. From there, the crawl loop produces new links, and routing those links to their owners produces more crawling. What remains is how lookup finds a key’s owner with no coordinator.
Consistent hashing: how the ring assigns ownership
We need one rule for deciding which node owns a given link, and it has to do two things: every node must arrive at the same answer, and that answer should barely change when nodes join or leave. Consistent hashing does both.
The hash space is a circle of numbers, starting at 0 and increasing clockwise until it wraps back to 0. We will draw it as 0 to 127 to keep the picture small, but a real system uses a much larger range, such as 0 to 2¹⁶⁰. Two kinds of things live on this circle:
- Nodes. A node’s position is the hash of its id. Five nodes might land at 12, 27, 52, 70, and 91.
- Links. A link’s position is the hash of the link. That position is the link’s key.
A link belongs to the first node clockwise from the link’s key.
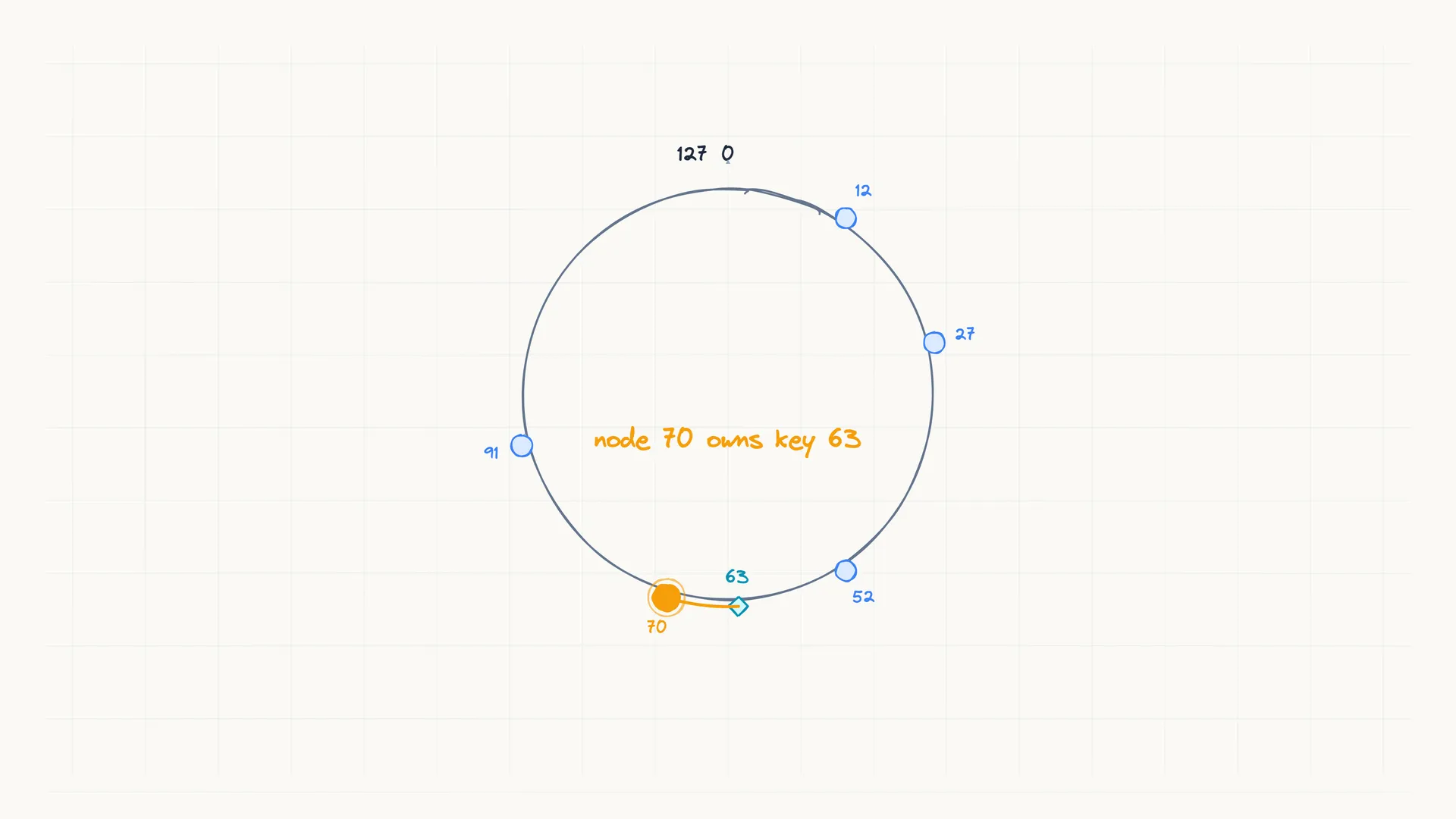
So a link with key 63 is owned by node 70, the next node clockwise after 63. Every node uses this same rule and reaches the same answer, so no central table and no coordinator is needed to assign owners.
Why a circle, instead of something simpler like numbering the nodes and using hash(link) % N? Because that scheme breaks whenever the set of nodes changes. Add or remove a single node and N changes, which moves almost every link to a different node and forces the whole web to be re-divided. On the circle, adding or removing a node only affects the links in the small arc next to it, and every other link keeps its owner. That stability is what “consistent” means here, and it matters because nodes join and leave constantly.
The rule tells every node how ownership works, but applying it requires knowing where all the other nodes sit on the circle. A node that only knows its immediate neighbors cannot look up “who is the first node clockwise from key 63” in a local table. It has to route the query around the ring, forwarding it node by node until it reaches the owner. That routing operation is lookup(key), and doing it efficiently when there are thousands of nodes is the first deep dive.
This whole arrangement, a set of nodes each responsible for one arc of the circle, is a distributed hash table, or DHT.
Deep dives
1) How does a lookup reach the owner?
The ring decides who owns a key, but a request still has to reach that node. How much each node knows about the rest of the ring determines how many hops a lookup takes. More knowledge means fewer hops, but also more state to keep up to date. There are three points on that spectrum.
| Approach | State per node | Lookup cost | Join/leave cost |
|---|---|---|---|
| Successor-only | O(1) | O(N) hops | O(1) |
| Full membership | O(N) | O(1) | O(N) per event |
| Finger table | O(log N) | O(log N) hops | O(log N) |
At one extreme, each node knows only the next node clockwise, its successor. A lookup for a key that lives far away walks the ring one hop at a time, forwarding the request to each successor until it reaches the owner. That is O(N) hops, which means thousands of network round trips in a 10,000-node ring.
At the other extreme, each node knows every other node. A lookup is a single local scan of that list, but every join or leave event has to be broadcast to all N nodes. Under constant churn, the update traffic alone becomes the bottleneck.
A finger table sits in between. Each node keeps about log₂ N entries, spaced at exponentially increasing distances around the ring: the first entry points to the node at offset +1, the second at +2, the third at +4, then +8, +16, and so on. When a node receives a lookup for some key, it forwards the request to the farthest finger that does not overshoot the target. Each hop roughly halves the remaining distance, so the lookup reaches the owner in about log₂ N hops.
Successor pointers and finger tables serve different roles. Successor pointers carry correctness: as long as every node knows its true successor, a lookup can always reach the owner by walking the ring one hop at a time. Finger tables only affect speed. If a finger entry is stale or missing, the lookup takes more hops but still arrives at the right node.
Every node periodically checks whether its successor is still alive and updates the pointer if the successor has changed, so successor pointers stay accurate even as nodes join and crash. Finger tables refresh less frequently. When the ring changes, correctness is restored quickly while routing performance catches up over time.
def lookup(key):
# base case: the key falls in my successor's range
if between(key, my_id, successor.id):
return successor
# forward to the farthest finger that precedes the key
for i in reversed(range(len(finger_table))):
if between(finger_table[i].id, my_id, key):
return finger_table[i].lookup(key) # network hop
return successor.lookup(key) # fallback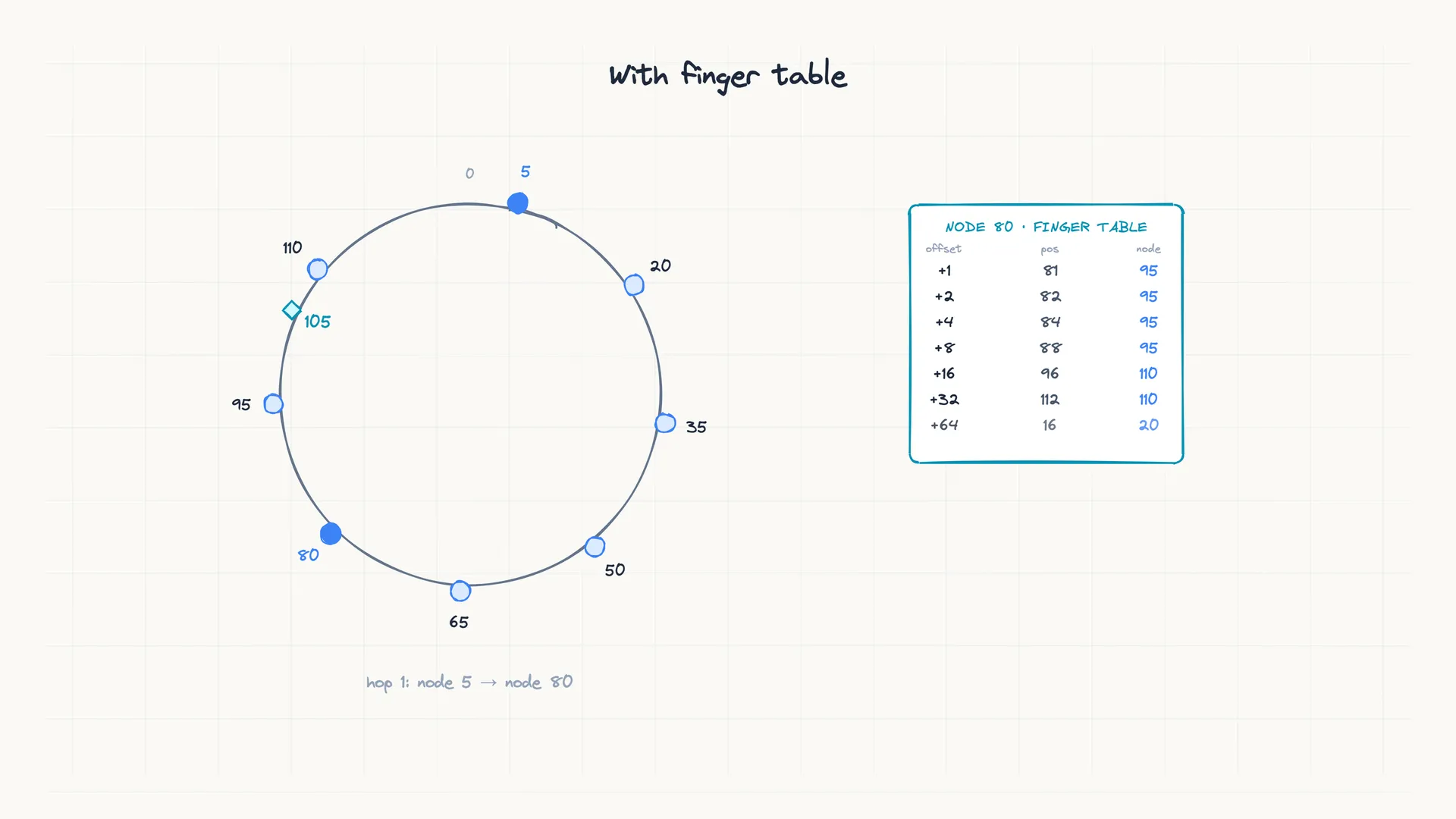
On a 0-127 ring with eight nodes, a lookup for key 105 starting from node 5 takes three hops: node 5 forwards to node 80, node 80 forwards to node 95, and node 95 returns its successor, node 110. Successor-only routing would take seven hops for the same lookup. Each hop is a network round trip handled by a different node using its own finger table. At 10,000 nodes, a lookup takes about 13 hops. At 50 milliseconds per hop, that is roughly two-thirds of a second.
2) How does a node join or leave the ring?
A new node needs to find where it belongs on the ring and link itself in. It starts by contacting any existing node. In practice, every deployment has a few hardcoded bootstrap nodes that serve as entry points into the network. The new node asks that bootstrap node to look up the successor for its position. Once it knows its successor, it inserts itself into the ring by updating its neighbors’ successor and predecessor pointers.
For example, suppose the ring has nodes 10, 40, 70, and 90. Node 55 wants to join. It contacts a bootstrap node, which runs lookup(55) and returns node 70, the first node clockwise after position 55. Node 55 links itself between 40 and 70. The ring becomes 10 → 40 → 55 → 70 → 90 → 10.
At this point the new node is in the ring, but it cannot route efficiently. It builds a finger table by running lookups at doubling distances around the ring. Other nodes’ finger tables also do not know about the new node yet, so lookups that should route through it take a few extra hops. This is temporary: each node periodically refreshes its finger table entries, and the new node gets picked up over time. Correctness is never affected, because correctness depends on successor pointers, which are already repaired.
The new node also needs state. Its successor previously owned the full key range that now includes the new node’s portion. The successor transfers the relevant slice of state, the seen set and task queue for those keys, to the new node. The successor keeps serving that range until the transfer is complete, so no tasks are lost during the handover.
def join(bootstrap_node):
successor = bootstrap_node.lookup(my_id) # find my place on the ring
link_as_predecessor_of(successor) # update neighbor pointers
for i in range(m): # build finger table
finger_table[i] = lookup(my_id + 2**i)
state = successor.transfer_keys(my_range) # receive my share of stateA graceful leave is the reverse. A node that is shutting down on purpose transfers its state to its successor and tells its neighbors to update their pointers. The ring closes the gap cleanly. The hard case is when a node disappears without warning.
3) What happens when an owner crashes?
A node can fail at any time without warning. The ring has to close the gap, and the owner’s seen set and task queue need to survive somewhere.
Ring repair. Each node keeps a successor list, an ordered list of the next few nodes clockwise, instead of a single successor pointer. Every node periodically checks whether its successor is still alive. If the check fails, the node moves to the next entry in the successor list, and the ring closes the gap without involving any other nodes.
State survival. Ring membership and shard state are handled separately. Each owner continuously replicates its seen set and task queue to its next K successors, where K is typically 2 or 3. These successor replicas hold a copy of the owner’s shard state. When an owner dies, the next successor in line detects the failure, promotes its replica to primary, and continues serving that key range.
Two factors bound what can still be lost despite replication. The first is K, the number of replicas. Data is lost only if the owner and all K replicas fail before replication catches up, which is unlikely at K of 2 or 3 but not impossible during a correlated failure like a rack power loss. The second factor is the replication window: the time between accepting a new task and replicating it to the successors. If the owner crashes inside that window, the task existed on only one machine and is gone.
How much that loss matters depends on the URL. On the open web, most pages have many inbound links, so another node will eventually discover the same URL through a different link and route it to the new owner. The loss is invisible. On the long tail, a page with only a single inbound link is never rediscovered if that one task is lost. Closing the replication window improves coverage but costs latency. There are three strategies for managing that tradeoff.
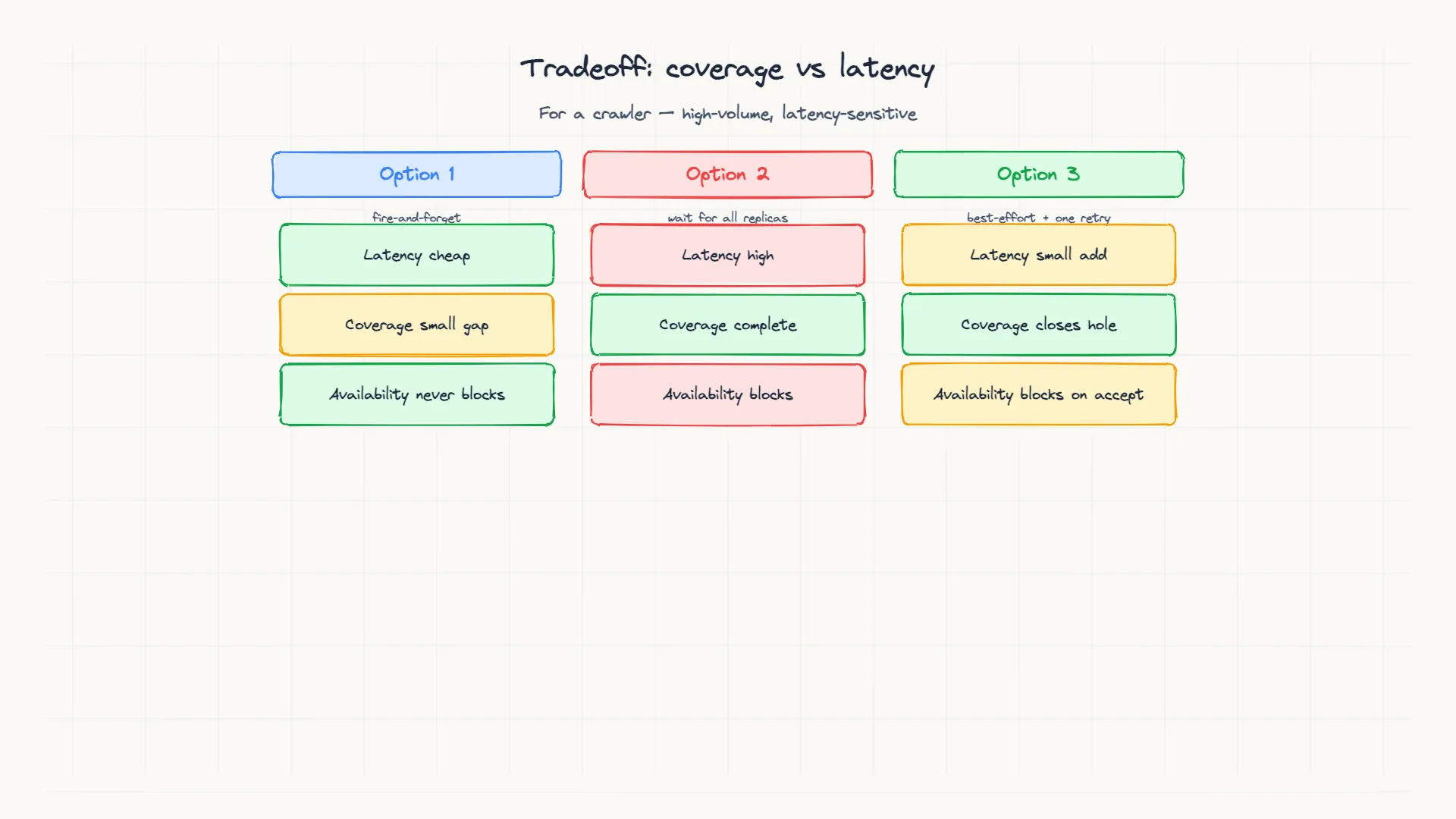
- Async (fire and forget): the owner accepts the task and replicates it some time later. The delay between acceptance and replication is the loss window. This is cheap and fast, but it leaks long-tail URLs during failures.
- Full sync: every write waits for all K replicas to acknowledge before the owner proceeds. There is no loss window, but every write pays the latency of the slowest replica, and the owner stalls if any replica is slow or unreachable.
- Sync-on-accept hybrid: replicate synchronously only when a new task is first accepted, the moment the URL enters the shard. Progress updates, like marking a URL as fetched, replicate asynchronously. This closes the window for new URLs without paying full-sync cost on every write.
When duplicate links make missed tasks recoverable and write latency matters most, async replication fits. When long-tail coverage is a hard requirement, sync-on-accept closes the loss window for new URLs without paying full-sync cost on every write. Full sync is rarely justified for a crawler. The practical result is eventual coverage: most pages get crawled once, some get crawled twice after a failure and recovery, and a few long-tail pages are lost to bad timing.
4) What if a crashed owner comes back?
A node can return after a brief absence and still believe it is the owner. Suppose node 55 goes offline during a network partition or a long garbage-collection pause. Its successor, node 70, detects the failure and takes over the key range. When node 55 comes back, it never saw the handover. It still considers itself the owner, starts accepting writes for the same key range, and begins updating its own seen set. Now two nodes both think they own the range, their seen sets diverge, and there is no clean way to merge them. This situation is called split-brain.
Ownership epochs fix it. Each key range carries a monotonically increasing counter, its epoch, that increments every time ownership changes hands. When node 70 takes over from node 55, the epoch goes from 3 to 4. Every write that node 70 sends to its replicas carries epoch 4 as a fencing token, a value that proves the writer is the current owner. The replicas store the highest epoch they have seen, and they reject any write with a lower epoch.
# on a replica: check the fencing token before accepting a write
def on_write(key_range, data, epoch):
if epoch < current_epoch[key_range]:
reject() # writer is stale
return
current_epoch[key_range] = epoch
apply(data)When node 55 returns and tries to write with its old epoch 3, the replicas refuse the write. That refusal is how node 55 learns it is stale. It can then query the ring, discover that node 70 is the current owner, and rejoin as a regular node. Ownership is decided by the ring and enforced by the epoch, not by a node’s own belief about itself.
Pattern: fencing tokens appear wherever a node can be presumed dead and then return to act on stale state, such as leader leases and distributed locks.
5) What should the crawl task key be?
The crawl task key is the value that gets hashed to place a URL on the ring and pick its owner. This single choice determines how evenly work is distributed across nodes, how well the crawler respects per-host politeness rules, and how much state is lost when a node fails. The choice is a spectrum of granularity.
| Key | Load balance | Politeness |
|---|---|---|
| Full URL | Best, URLs scatter evenly | Worst, a site’s load spreads across nodes and nobody sums it; no single owner for robots.txt |
| Hostname + path segment | Splits hot hosts | Splits robots.txt across nodes |
| Hostname | Worst, a giant host is one hot shard | Best, one owner for robots.txt, rate limit, dedupe |
A middle option is hostname plus the first path segment, such as youtube.com/watch versus youtube.com/channel. This splits very large hosts across several owners, but it also splits robots.txt and rate-limit responsibility, so no single node controls politeness for the whole host.
Full-URL keys give the best load distribution, because individual URLs scatter evenly across the ring. But they break politeness. A single site’s pages end up spread across many different nodes, each node rate-limits its own fetches independently, and no node sees the total request rate to that host. When a node discovers a site with thousands of links, it sends those links to many different owners at once, which can overload a small server and get the whole crawler blocked. There is also no single place to check or cache the host’s robots.txt.
Hostname keys are the opposite. Every URL on youtube.com hashes to the same node, which becomes the single authority for that host’s robots.txt, crawl delay, and dedupe. The cost is a hot shard: a host with tens of millions of pages is more work than one node can fetch alone. UbiCrawler, an early decentralized crawler built on hostname ownership, ran into exactly this problem.
Which key to use depends on the deployment. When the crawler belongs to one organization and politeness is a hard requirement, hostname keys are a natural fit: one owner per host can enforce robots.txt, rate limits, and dedupe in one place.
The hot-shard problem does not require switching to a different key. The owner keeps the control plane (politeness rules, rate limiting, and dedupe) and delegates the actual fetching to its successor replicas, which already exist for fault tolerance. The owner assigns fetch batches to these replicas, turning them into helpers that execute fetches under the owner’s rate limit.
When even load distribution matters more than per-host coordination, full-URL keys are a better fit.
6) How far does this scale?
Storage per node. Each entry in the seen set is an 8-byte hash of a URL. A Bloom filter, a compact probabilistic set, uses fewer bits per element but occasionally reports a new URL as already seen (a false positive). The formula is about 1.44 · log₂(1/fp) bits per element, where fp is the false-positive rate. A false positive means a page is permanently skipped, because a standard Bloom filter has no way to remove an entry once it is added.
| URLs per node | Exact set (8 bytes each) | Bloom filter |
|---|---|---|
| 100 million | 800 MB | ~120 MB at 1% false-positive rate |
| 1 billion | 8 GB | ~1.2 GB at 1% |
| 10 billion | 80 GB | ~18 GB at 0.1% |
An exact set is the right choice as long as the node has enough memory. Past that point, a Bloom filter trades a small, permanent coverage loss for much lower memory use. The false-positive rate is a tuning knob: a lower rate means better coverage but more memory per element.
Network size and churn. With finger-table routing, a lookup takes about log₂(N) hops. At 10,000 nodes, that is roughly 13 hops. At 50 milliseconds per hop, a single lookup takes about two-thirds of a second. Each entry in a finger table has to be periodically refreshed to stay accurate, so more entries means more background maintenance traffic. Full membership routing generates O(N²) network-wide update traffic, because every node must track every other node. Finger tables bring that down to O(N log N).
If nodes join and leave faster than the finger tables can refresh, the fingers go stale and lookups take more hops, falling back toward O(N) in the worst case. But lookups stay correct, because correctness depends only on the successor pointers, which are maintained by the same periodic check-ins that handle joins and crashes. Finger tables affect lookup speed, not lookup correctness.
The whole design follows from one constraint: there is no coordinator.
The video version on Scalable Thoughts covers each mechanism in more detail. Subscribe if you want more system design content like this.